
성능 체크하는 방법
1. EXPLAIN
EXPLAIN SELECT문;
EXPLAIN SELECT * FROM customers;
SELECT 앞에 EXPLAIN을 붙이면 데이터를 얼만큼 찾아보고 찾아냈는지, 찾아본 데이터의 수가 총 몇 개인지 설명해준다.

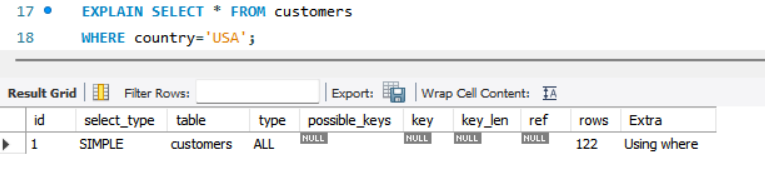
LIMIT이나 WHERE를 사용해도 전체 데이터를 조회한다.
=> 조건이 맞는지 안 맞는지 마지막 데이터까지 확인해보기 때문에, 어떤 조건을 달아도 결국 데이터를 다 찾아보게 된다.
2. 프로파일링 (profiling)
SET profiling = 1; # profiling 기능 켜는 설정
SELECT * FROM customers WHERE country = 'USA';
SELECT * FROM post WHERE createdAt > '2024-12-02';
SELECT COUNT(*) FROM post WHERE createdAt > '2024-12-02';
EXPLAIN SELECT * FROM post WHERE createdAt > '2024-12-02';
SHOW PROFILES; # profiling 결과 조회
SHOW PROFILE FOR QUERY 21; # 특정 쿼리의 실행 과정 상세 조회
=> 내부적으로 동작하는 과정들 출력
profiling을 1로 설정하여 활성화 후 SELECT 문을 실행한 다음에
SHOW PROFILES 을 실행하면 쿼리의 ID와 시간이 나온다.
특정 쿼리의 실행 과정을 상세 조회하고 싶으면 쿼리의 ID를 입력해서 상세 조회하면 된다.

실습
테이블 생성
CREATE TABLE member
(
idx INT AUTO_INCREMENT PRIMARY KEY,
email VARCHAR(30),
nickname VARCHAR(20),
createdAt DATETIME
);
CREATE TABLE post
(
idx INT AUTO_INCREMENT PRIMARY KEY,
writerIdx INT,
contents VARCHAR(100),
createdAt DATETIME,
FOREIGN KEY (writerIdx) REFERENCES member(idx)
);
sql 파일 import 하기
1. Server 탭 - Data Import
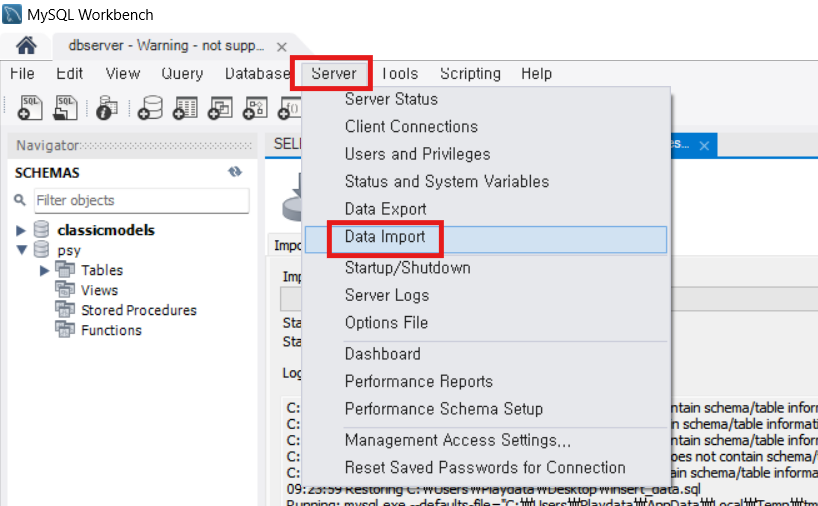
2. Import from ~ File 체크 후 ... 눌러서 파일을 선택
3. Default Schema로 Import 할 디비를 선택하고 Start Import 클릭

성능 개선하는 방법
1. INDEX
목차, 색인을 생성하는 것 = 목차를 기준으로 정렬
SELECT * FROM post WHERE createdAt > '2024-12-02';

57만개를 조회하는 것을 확인할 수 있음.
CREATE INDEX 인덱스 이름 ON 테이블(속성);
CREATE INDEX post_index_createdAt ON post(createdAt); # 인덱스 생성
DROP INDEX 인덱스 이름 ON 테이블;
DROP INDEX post_index_createdAt ON post; # 인덱스 삭제
EXPLAIN으로 봤을 때 같은 쿼리를 실행했을 때 더 적은 행을 조회하는 것을 볼 수 있다.

show profiles 로 봤을 때도 시간이 더 빨라진 것을 확인할 수 있다.

JOIN 실습
SELECT post.idx, post.contents, member.email
FROM member LEFT JOIN post
ON member.idx = post.writerIdx
WHERE member.nickname='User1'
ORDER BY post.idx DESC
LIMIT 0, 10;
EXPLAIN으로 봤을 때 9만 9천개를 조회한다.

시간도 3초로 꽤 오래 걸린다.
CREATE INDEX member_index_nickname ON member(nickname);
조건을 기준으로 INDEX를 생성하게 되면 행을 하나만 조회한다.

시간도 더 빨라진 것을 확인할 수 있다.

2. 스토어드 프로시저
: SQL이 실행될 때 진행하는 일련의 과정을 미리 실행해서 저장해두고, 나중에 그걸 사용하는 기능
원래 인터프리터 언어인 SQL을 미리 컴파일 시켜서 좀 더 빠르게 실행할 수 있게 한다.
=> 실제 실무에서 많이 사용한다.
# 프로시저 생성
DELIMITER $$
CREATE PROCEDURE SP 이름 (IN 또는 OUT 속성)
BEGIN
SELECT 문;
END $$
DELIMETER ; # 문장 구분
# 프로시저 사용
CALL SP 이름;
IN 또는 OUT 속성에는 WHERE절 등에서 조건으로 들어온 속성을 넣는다.
DELIMITER $$
CREATE PROCEDURE SP_SELECT_MEMBER ()
BEGIN
SELECT * FROM member;
END $$
DELIMETER ;
CALL SP_SELECT_MEMBER();
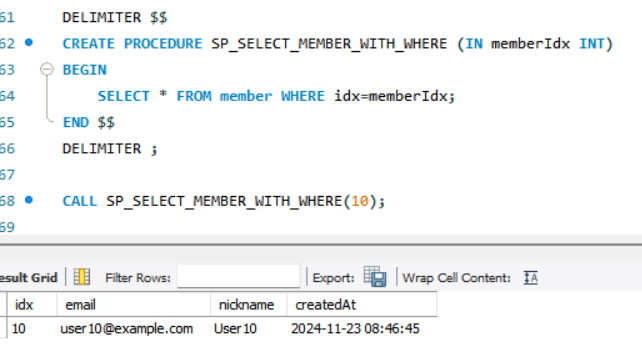
DELIMITER $$
CREATE PROCEDURE SP_SELECT_MEMBER_WITH_WHERE (IN memberIdx INT)
BEGIN
SELECT * FROM member WHERE idx=memberIdx;
END $$
DELIMETER ;
CALL SP_SELECT_MEMBER_WITH_WHERE(10);
이렇게 하면 SP 이름으로 쿼리를 실행할 수 있게 된다.
문장을 구분하기 위에 마지막에 DELIMETER ; 를 붙여줘야 한다.
3. 뷰
= 가상 테이블
- JOIN을 했을 때의 테이블을 가상으로 만들어 놓는 것.
- 여러 개의 테이블을 합친다거나 복잡한 쿼리를 실행할 때 테이블을 뷰로 만들어 놓으면 쉽게 조회할 수 있다.
CREATE VIEW 뷰 이름
AS
SELECT - JOIN 문
SELECT * FROM 뷰 이름;CREATE VIEW view_post_join_member
AS
SELECT post.idx, post.contents, member.email
FROM member LEFT JOIN post
ON member.idx = post.writerIdx
ORDER BY post.idx DESC;
SELECT * FROM view_post_join_member;
성능에 영향을 가장 많이 끼치는 순서는
INDEX -> 스토어드 프로시저 -> 뷰
역색인
: 키워드를 통해서 데이터를 찾아내는 기능이다.
- 특정 키워드를 통해 찾아내는 방식이라 속도가 빠르다.
- 관계형 데이터베이스는 이 기능이 없다.
Elastic Search
- 기본적으로 역색인을 생성해서 역색인을 기반으로 데이터를 검색한다.
- 관계형 데이터베이스는 아니고, NoSQL 서버 중 하나
반정규화
# 게시글 조회 화면에서 다음과 같이 나올 수 있는 SQL
# [게시글 번호] [게시글 작성자] [게시글 내용] [게시글 작성 시간] [게시글의 좋아요 수]
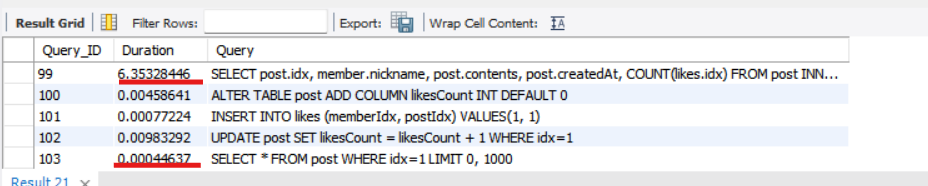
SELECT post.idx, member.nickname, post.contents, post.createdAt, COUNT(likes.idx)
FROM post
INNER JOIN member
ON post.writerIdx = member.idx
LEFT JOIN likes
ON post.idx = likes.postIdx
GROUP BY likes.postIdx
ORDER BY post.idx ASC;
위의 쿼리를 실행하는 데 7초나 걸린다.
반정규화를 해서 like를 저장할 때 post 테이블의 like 수 자체를 증가하게 해놓으면 매번 join을 안 해도 된다.
=> 성능이 더 빨라진다.
ALTER TABLE post ADD COLUMN likesCount INT DEFAULT 0;
INSERT INTO likes (memberIdx, postIdx) VALUES(1, 1);
UPDATE post SET likesCount = likesCount + 1 WHERE idx=1;
SELECT * FROM post WHERE idx=1;
이렇게 속성을 미리 만들어 놓으면 속도가 더 빨라지는 것을 확인할 수 있다.
반정규화를 할 때는 반드시 데이터의 일관성을 유지할 수 있는 장치가 필요하다.
기타 SQL 성능 최적화 문법
## 필요한 데이터만 조회
SELECT * FROM member WHERE idx < 10;
SELECT idx, email FROM member WHERE idx < 10;
## LIMIT 및 페이지 활용
SELECT * FROM post ORDER BY createdAt DESC;
SELECT * FROM post ORDER BY createdAt DESC LIMIT 0, 10;
## 서브쿼리 대신 JOIN 사용
SELECT
post.idx,
(SELECT email FROM member WHERE idx = post.writerIdx) AS writer,
contents,
post.createdAt
FROM post;
SELECT post.idx, member.email AS writer, contents, post.createdAt
FROM post
JOIN member ON post.writerIdx = member.idx;
'CS > DB' 카테고리의 다른 글
| [DB] 재해 복구(DR) / DB 서버 Replication 설정 / 미러 사이트 구성 실습 (0) | 2024.12.03 |
|---|---|
| [DB] JMeter 부하 테스트 (2) | 2024.12.02 |
| [DB] SQL 코테 문제 풀어보기 (프로그래머스) (3) | 2024.11.29 |
| [DB] SQL 문법 (1) | 2024.11.29 |
| [DB] 워드프레스 서버 - DB 서버 연동 실습 (2) | 2024.11.28 |